AI · Engineering · Product · Systems · Debugging
Six PRs, One Bug: What AI Agents Actually Get Wrong
A billing email bug took six AI-authored PRs to diagnose—not because the agent couldn't write code, but because it never promoted a repeated local failure into a structural question. The full session log shows exactly how it happened.
Essay
On April 4, 2026, I opened issue #159 in my Friends & Family Billing app. The bug looked small enough to be annoying, not interesting: the invoice template editor showed one thing, Preview showed another, and the email that actually went to customers showed a third.
That framing turned out to be wrong.
This was not a styling bug. It was a systems bug wearing a styling-bug costume. Over roughly twenty hours, one agent opened six PRs trying to resolve it: #144, #146, #153, #154, #155, and #158. None fixed the user-facing problem. PR #161 finally did, but only after a different agent, given a fundamentally different kind of prompt, treated the whole thing as a failed-fix investigation instead of another incremental patch.
The lesson is not "AI is bad at formatting." The lesson is that agents are very good at making local progress inside the wrong model, and that the difference between six failed fixes and one successful one was not a smarter agent. It was a different supervision structure.
I have the full session log: eighteen user prompts, nine external code review rounds, three automated stop-hook interventions, and the task document that finally produced the fix. This post is about what that record shows.
The invariant was simple
If a template editor is going to be trustworthy, it has to preserve one basic invariant:
Editor = Preview = Sent emailHere is what the actual pipeline looked like after the TipTap migration:
Editor: TipTap / ProseMirror document -> Editor DOM
Preview: TipTap / ProseMirror document -> docToPlainTextWithTokens() -> CommonMark renderer -> Preview HTML
Email: TipTap / ProseMirror document -> docToPlainTextWithTokens() -> Regex-based renderer -> Sent email HTMLThe editor rendered structured content directly. Preview and send did not. They first flattened that structured document back into markdown-like plain text, then reparsed it through two different HTML pipelines.
Once that happened, "WYSIWYG editor" stopped being true in any meaningful sense. The same content was no longer guaranteed to produce the same semantics.
What the screenshots were actually saying
The screenshots in issue #159 are not just visual proof that something looked off. They are evidence that different layers of the system were interpreting the same content differently.
1. Editor: the structured document still looked sane
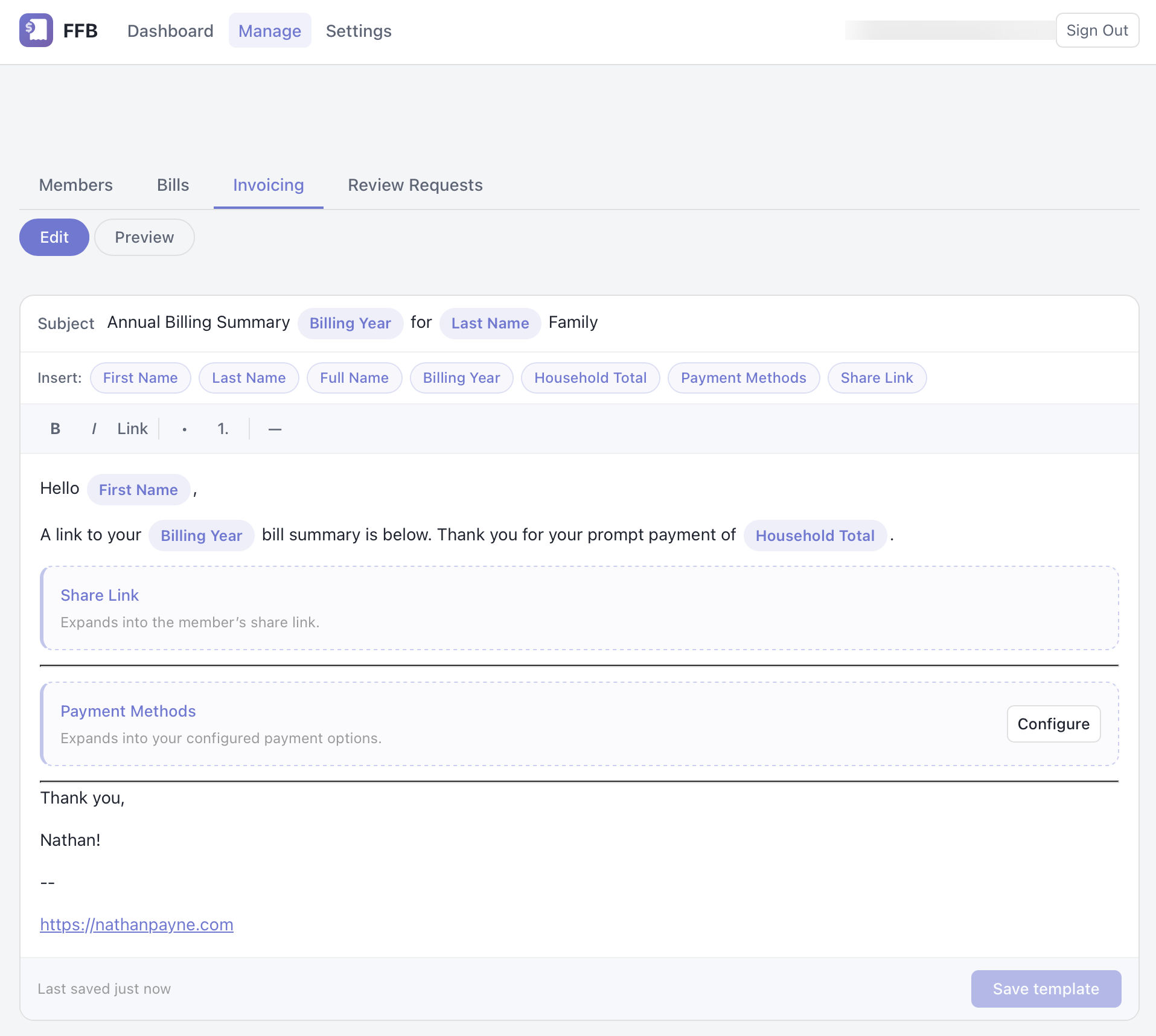
In Edit mode, the intro paragraph is ordinary body text. The billing-summary link, payment options block, divider, and signature are all in the expected order. At this point the content still lives as structured TipTap / ProseMirror JSON, so the system has not yet lost information.
2. Preview: semantics changed during the markdown round-trip
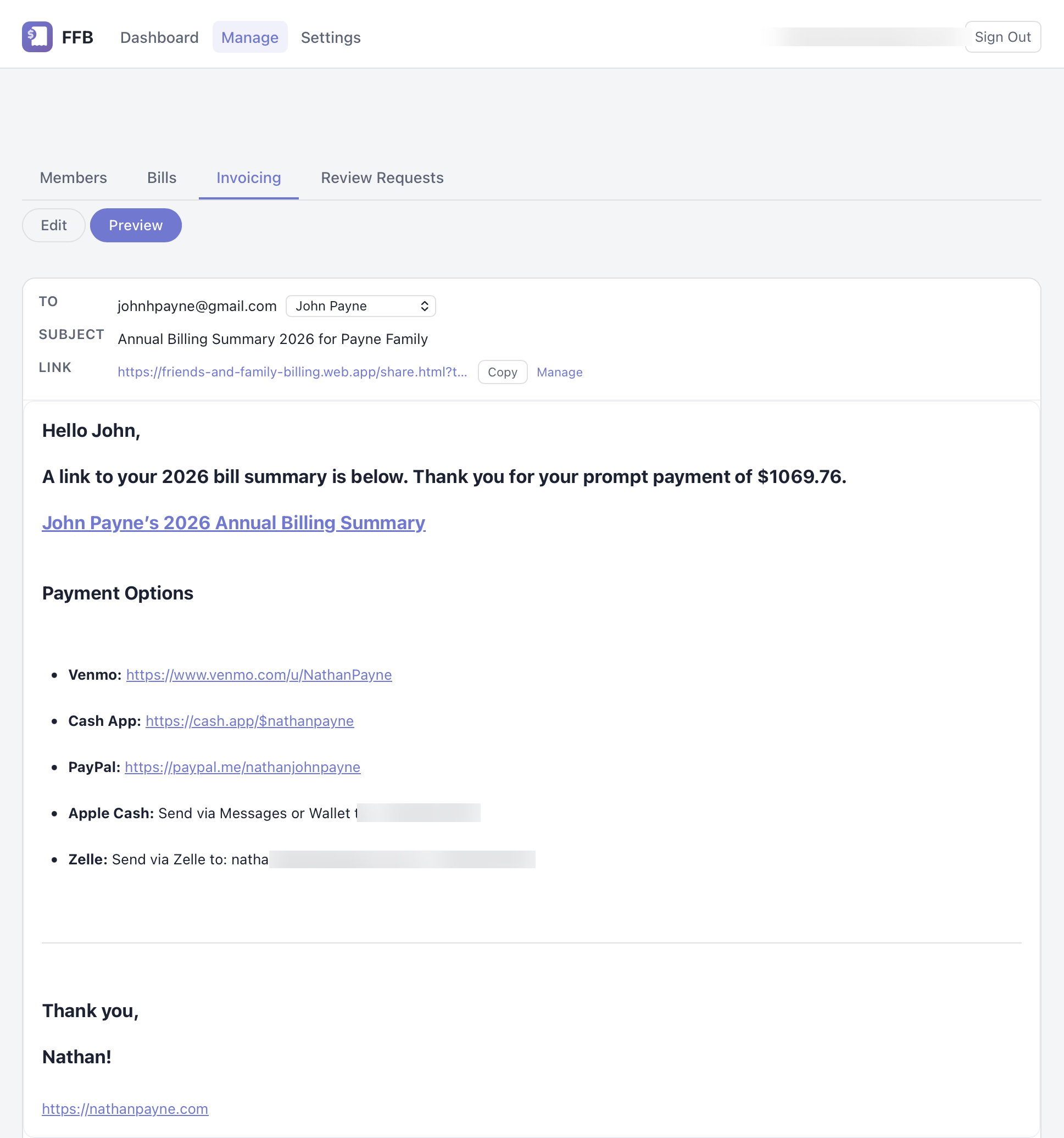
Preview was not rendering the editor document directly. It serialized the document into markdown-like text and reparsed that text with CommonMark. Separator lines like --- were being interpreted differently across surfaces, and list content was picking up paragraph wrappers with default margins. That is why the Preview screenshot looks heavier and more spread out than the editor even though the author never changed the template content.
3. Sent email: a second parser created a third version of reality
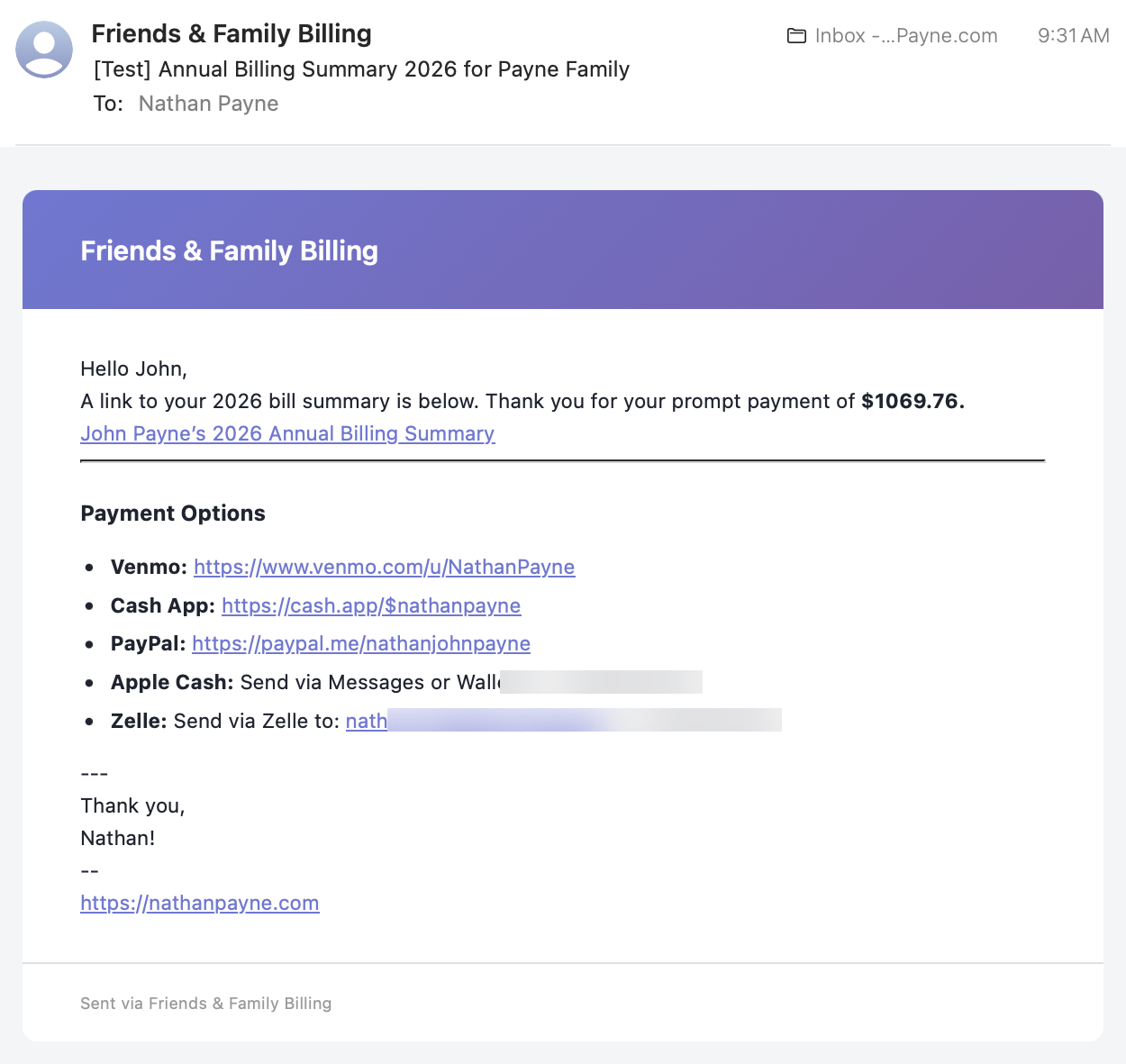
The sent email did not use the Preview renderer. It took the same flattened text and pushed it through a separate regex-based markdown renderer in the Cloud Function. So by the time the email reached a customer inbox, the system had already turned one source document into three different interpretations: editor, preview, and email.
4. The target was concrete, not hypothetical
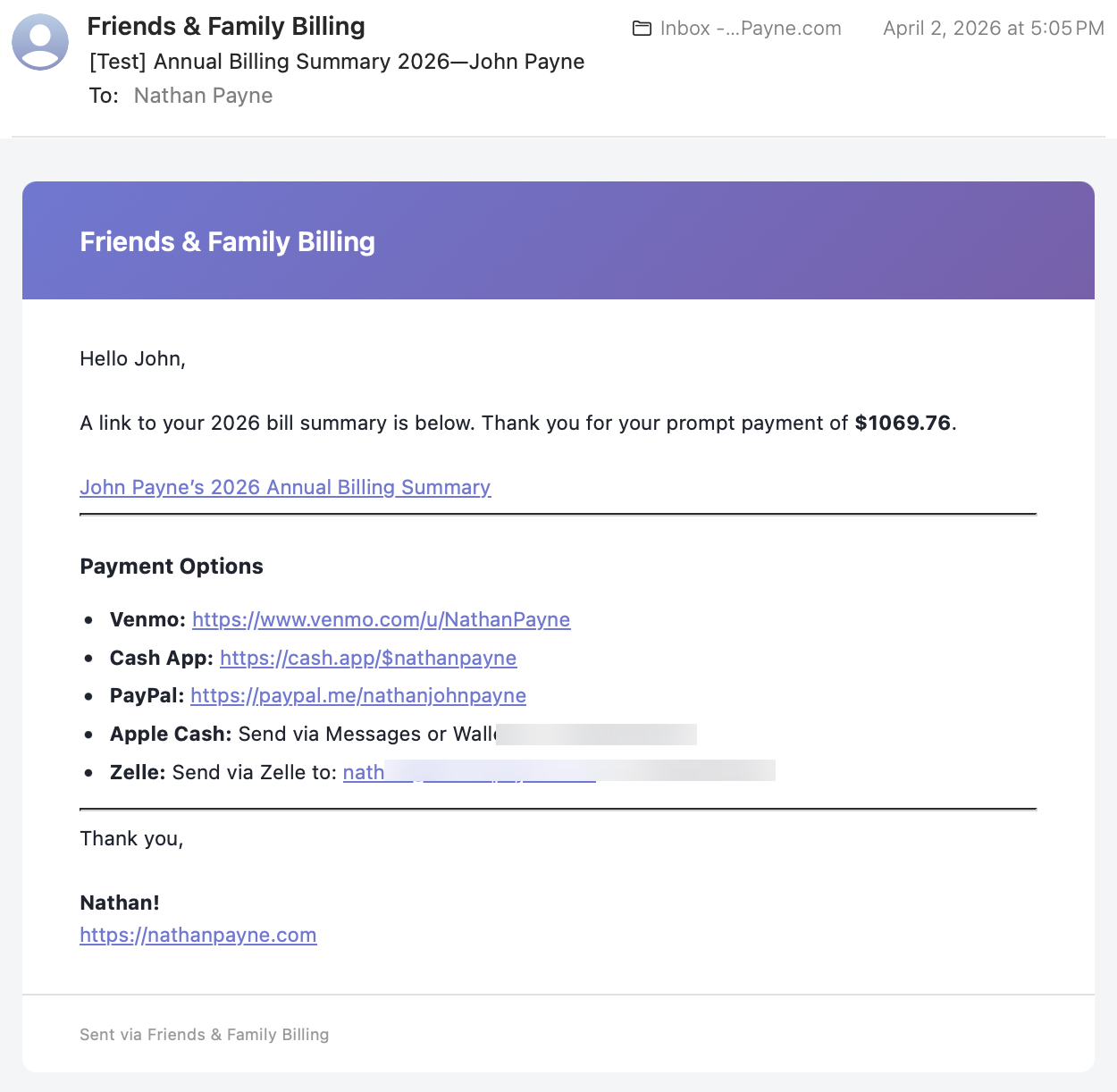
This detail in the issue mattered: there was a known-good email from April 2, 2026 at 5:05 PM. The bug was not "make Preview look a little nicer." The bug was "restore parity with a real output that previously existed."
That is an important debugging difference. When a target is concrete, the work becomes a parity problem, not a taste problem.
What I actually said to the agent
I have the full session transcript. Here is how I described the bug across four separate prompts:
Prompt 6 (first report, two screenshots):
The text shows bold in preview, but not in the editor.
Prompt 7 (second report, two screenshots):
The bold issue is still there. It does not get fixed by bolding and unbolding, it doesn't work at all. To add insult to injury, the app is now loading slowly or failing to reload, even after restarting the browser. Look hard this time, you keep missing something.
Prompt 9 (third report, five screenshots of a full reload cycle):
The same message, verbatim. I had already run out of new ways to describe the problem. The only thing that changed was the evidence: two screenshots became five, showing the full reload cycle from dashboard to editor to preview, proving the bug survived a hard refresh. The words were identical because the bug was identical. The agent had changed code between these prompts. The output had not changed.
Prompt 11 (desperation):
Given this is a simply single email template, maybe it is okay to sacrifice to get it right?
By prompt 11, I was offering to throw away the template rather than keep watching the agent fail. Every developer who has used an agent for more than ten minutes will recognize this arc: you start by describing a bug, escalate to "you keep missing something," send the same message twice because the bug is the same, and end by questioning your own requirements.
Notice what I never said in any of those prompts. I never said "Preview and email must use the same rendering path." I never said "the markdown bridge is the wrong architecture." I never said "audit your previous fixes before trying again." I described the symptom each time, more urgently, and expected the agent to promote the symptom into a structural diagnosis.
It did not.
Why six PRs still did not fix it
The failed PRs show how an agent can keep doing competent work without ever repairing the invariant. This was Claude Code on the failed attempts and OpenAI Codex on the successful one, but I do not think this is mainly a vendor story. The session log makes clear that the difference was in the prompt structure, not the model.
PR #144: the migration preserved the old assumption
PR #144 introduced the TipTap WYSIWYG editor. That sounds like the architectural answer. In practice, it preserved the old pipeline by explicitly bridging the new structured document back into the existing plaintext workflow.
The crucial idea in the PR description was: keep docToPlainTextWithTokens() as the bridge and leave the old invoice body builder in place.
That decision made the rest of the bug almost inevitable. The app now had a rich-text editor as the authoring surface, but Preview and send still depended on a lossy intermediate format. The structured document was treated as temporary.
My kickoff prompt for the session was:
Read invoicing-tab-redesign.md and implement the plan.
Here is the part that makes this harder to dismiss as "bad prompting": that design spec was good. It was a 520-line document that explicitly chose TipTap JSON as the canonical storage format, explained why ("persisting HTML would require round-tripping through TipTap's HTML parser/serializer on every load/save cycle, which is lossy"), and described the derived output model clearly: "HTML is generated from JSON for Preview rendering. Email-safe HTML is generated from JSON for final outbound email rendering."
That last sentence is essentially the invariant. The spec described a system where JSON is the source of truth and both Preview and email are derived from it through HTML generation.
But the spec also included a backward-compatibility requirement:
buildInvoiceBodyininvoice.jsmust handle: (1) Legacy plain-text templates containing%token%syntax (read fromsettings.emailMessage), (2) The new TipTap JSON document format (read fromsettings.emailMessageDocument)
That requirement created the bridge. The agent had to keep the old plaintext pipeline working alongside the new JSON format. PR #144's decision to flatten the structured document back into plaintext via docToPlainTextWithTokens() and run it through the existing buildInvoiceBody was a reasonable interpretation of "handle both formats"—convert the new format into the old one and reuse the existing pipeline. It is the lazy interpretation, but it is not an unreasonable one. The spec did not say "you must create a new email renderer that operates directly on the JSON document." It said the old function must handle both formats, and the simplest way to handle both is to convert the new one into the old one.
This matters because it means the failure was not "the agent had bad instructions." The spec implied the right architecture. The agent read the spec and made a locally rational decision that violated the spec's intent without violating its letter. Even well-written specs can leave enough room for an agent to choose the path of least resistance, and the path of least resistance is almost always "preserve the existing pipeline."
The takeaway is subtler than "state your invariant explicitly." It is: when a spec describes a new architecture but also requires backward compatibility with the old one, the agent will optimize for the compatibility constraint and sacrifice the architectural one. The invariant needs to be stated as a constraint that outranks backward compatibility, not implied by the storage format choice.
PR #146: the agent got better at regex, not closer to the invariant
PR #146 fixed bold-token round-tripping by making the serializer emit bold-wrapped token markers and tightening the token regex:
const token = '%' + id + '%';
const hasBold = n.marks?.some(m => m.type === 'bold');
return hasBold ? '**' + token + '**' : token;
const tokenPattern = /\*\*%([a-z_]+)%\*\*|%([a-z_]+)%/g;This is a perfectly reasonable patch if you assume the markdown bridge is the right architecture and the problem is only that the bridge is slightly lossy.
But that assumption was the bug.
Here is the part that makes the session log valuable: my automated code review agent, nathanpayne-codex, flagged exactly this problem in its review of PR #146:
Exact bold-wrapped tokens are not round-trip safe.plainTextToDoc("%first_name%")creates a bold-marked token node, butdocToPlainTextWithTokens()serializes it back to%first_name%.
The review identified the round-trip lossiness. The agent fixed the specific regex. It did not ask why the round-trip existed.
PR #153: one part semantic patch, one part visual patch
PR #153 contains two different kinds of reasonable fix in one diff, which is why it is my favorite example.
On the serialization side, it started wrapping inline marks back into markdown:
if (marks.some(m => m.type === 'bold')) result = '**' + result + '**';
if (marks.some(m => m.type === 'italic')) result = '*' + result + '*';On the presentation side, it collapsed preview spacing with CSS:
.invoice-preview-message li p { margin-bottom: 0; }
.invoice-preview-message li p + p { margin-top: 2px; }Both changes are locally valid. They probably improved the experience. They also show exactly how agents get trapped: one fix assumes the problem is markdown fidelity, the other assumes the problem is preview styling, and neither fix removes the reason formatting can drift between surfaces at all.
PR #154 and PR #155 fixed real bugs, just not this one
PR #154 fixed an editor lifecycle problem where useEditor was recreating the editor on every keystroke. PR #155 improved migration from legacy markdown into TipTap marks so bold, italic, and links were not displayed literally in the editor.
Those were both good fixes. They were also orthogonal to editor/preview/email parity. This is another failure mode worth noticing: an agent working on the right issue can still accumulate adjacent wins that make everyone feel progress is happening while the core invariant remains broken.
The review feedback on PR #155 is telling. The nathanpayne-codex reviewer flagged three separate round-trip safety issues: link parsing that stopped at the first ) in a URL, italic-wrapped links that did not survive serialization, and marked token forms that were not covered. Three findings, all pointing at the same structural problem, the intermediate format was lossy, and the agent addressed each one as a scoped regex fix.
PR #158: the bridge got cleaner, and the system stayed wrong
PR #158 is where sunk cost becomes obvious. The serializer logic was extracted into a lightweight template-doc.js, and adjacent marked segments were merged so TipTap would not emit markdown like this:
**word1****word2**The new module even documented the behavior carefully:
// Merge adjacent TEXT segments with the same non-link marks.
// This prevents **text1****text2** when TipTap splits text at boundaries.Again: technically competent work. Better module boundaries. Better performance. Better round-tripping.
Still the wrong system.
The review caught it again. nathanpayne-codex flagged that "the new adjacent-mark merge logic is lossy across token boundaries"—a bold token followed immediately by bold text was serializing as %first_name% owes. That is the third time in three PRs that a review round identified a round-trip safety failure in the serializer. Three times the feedback pointed at the architecture. Three times the agent patched the implementation.
By this point the agent had invested significant effort in making the intermediate serializer smarter and cheaper, which made it even harder to ask the more uncomfortable question:
Why does this serializer exist at all?The automated guardrails saw it too
The session included three automated stop-hook interventions, system-level checks that fire between prompts. Two of them are relevant:
Hook 2 flagged that the plaintext fallback was being derived from editor.getText() instead of the invoice renderer. With the TipTap schema, getText() was adding extra blank lines around block tokens and dropping list markers. This is the divergent-render-path problem stated as an automated finding: the system was generating plaintext from a method that did not match the rendering pipeline.
Hook 3 flagged that preview and test share-link generation still hardcoded familyMembers[0] even though Preview now let the user choose another member. A data consistency bug in a UI that was supposed to be showing you what the email would look like.
The guardrails were identifying the right class of problem. The agent kept treating each finding as a scoped fix.
What I gave the second agent
The prompt that produced PR #161 was structurally different from anything I said during the first session. It was not a bug report. It was a task document titled "Codex Task—Investigate Failed Fixes (Issue #159)."
It opened with this framing:
Multiple fixes have already been attempted by Claude Code and did not resolve the issue. You MUST treat this as a failed-fix investigation, not a greenfield implementation.
Then it listed all six failed PRs and required the agent to audit each one before writing a single line of code. The task was organized into eight steps. Steps 1 through 3 were pure reading: understand the issue, audit the failed fixes, identify the root cause. No code until step 4.
It stated the invariant as a non-negotiable requirement:
There must be one canonical rendering pipeline. At minimum, Preview and Sent Email must be generated from the exact same rendering path.
And it included a constraints section that explicitly banned the exact moves Claude Code had made across six PRs:
- Do NOT add another layer of transformation
- Do NOT "fix" by overriding CSS only
- Do NOT leave multiple rendering paths in place
- Do NOT rely on regex to fix formatting
- Do NOT optimize for minimal diff over correctness
Every constraint corresponds to something the first agent actually did. The CSS patch in PR #153. The regex improvements in #146 and #155. The additional transformation layer in #158. The minimal-diff optimization throughout. This was not a generic best-practices list. It was a list of specific mistakes extracted from the session history.
The task document also required the agent to deliver an audit of the prior fixes as part of the PR, not just the code, but an explanation of which assumptions were wrong and which abstractions made the problem worse. And it required regression tests proving that Preview output and email output were structurally equivalent.
What finally worked
Once the prior attempts were lined up side by side, the shared assumption became obvious: every fix preserved the markdown bridge. So the successful fix removed it.
The core addition was a canonical renderer for invoice templates:
export function buildInvoiceTemplateEmailPayload(ctx, shareUrl) {
return {
html: renderInvoiceTemplate(ctx, shareUrl),
text: buildInvoiceBody(ctx, 'text-only', shareUrl, 'email'),
};
}Then the app started using that same renderer for both Preview and the sent email payload:
previewEmailPayload = buildInvoiceTemplateEmailPayload(ctx, previewShareUrl);
previewBodyHTML = previewEmailPayload.html || renderInvoiceTemplate(ctx, previewShareUrl);
await queueEmail({
to,
subject,
body: payload.text,
html: payload.html,
uid
});The Cloud Function was updated to send trusted app-generated HTML when it was provided instead of reparsing markdown again. The winning fix did not become more sophisticated about formatting. It became simpler about boundaries.
The architecture after the fix:
Editor: TipTap / ProseMirror document -> Editor DOM
Preview: TipTap / ProseMirror document -> Canonical template renderer -> Preview HTML
Email: TipTap / ProseMirror document -> Canonical template renderer -> Sent email HTMLOne source document, one semantic rendering path, multiple consumers.
The difference was not the model
It would be easy to read this as "Codex is better than Claude Code at architecture." I do not think that is the right conclusion.
Claude Code received eighteen prompts over twenty hours. In that time, it also received nine rounds of code review feedback from an automated reviewer that correctly identified round-trip safety failures three separate times. It received three stop-hook interventions that flagged data consistency problems in the rendering pipeline. It had more information about what was wrong than the Codex agent ever did.
The difference was in what the prompt asked the agent to do with that information.
Every prompt I gave Claude Code described the current symptom: "bold in preview but not editor." Each time, the agent did what a competent developer would do if you walked up to their desk and said "this looks wrong"—it found the nearest code path that could explain the symptom and patched it. That is not a failure of intelligence. It is a failure of framing.
The Codex task document did not describe the current symptom at all. It described a pattern of failed fixes and asked the agent to explain why they failed before proposing anything new. It stated the system invariant explicitly. It banned specific classes of patches. It required an audit as a deliverable.
That is a different kind of work. It is not "fix this bug." It is "explain why this bug has survived six attempts to fix it, and address the underlying cause." Any agent—Claude, Codex, Gemini, a future model—will behave differently when the task is framed that way.
What I changed after this
After this issue, I turned the lesson into repo policy. Three rules:
The two-strike rule. If an agent has already made two failed fix attempts on the same problem, the third attempt must begin with an audit of the previous PRs. The agent has to explain what each prior fix assumed and why the assumption was wrong before it proposes a new fix. This prevents the patch-accumulation loop that produced PRs #146 through #158.
The serialization checklist. If a bug involves serialization or deserialization—content crossing a format boundary—the code review now asks three questions:
- Is the round-trip lossless?
- Do all consumers of the format produce equivalent output?
- Is the intermediate format even necessary?
Those three questions would have caught this bug at PR #144. They are simple, but they target the exact blind spot that agents have: they will improve a bridge indefinitely without asking whether the bridge should exist.
Constraint-driven prompts for system bugs. When a bug touches more than one layer of the system, the prompt now includes an explicit list of banned approaches derived from prior failures. Not "best practices" in the abstract—specific things this codebase has already tried that did not work. The agent needs to know what the search space does not include.
Invariants outrank backward compatibility. This is the lesson from the design spec. A spec can describe the right architecture and still leave room for an agent to build a bridge to the old one if it also requires backward compatibility. When both are present, the spec now states which constraint wins. "The new rendering path is the canonical path. Legacy format support is a migration concern, not an architectural peer."
What AI agents actually get wrong
The agent was not failing because it could not write code. Every PR compiled, passed tests, and improved something locally. The serializer got more faithful. The CSS got tighter. The module boundaries got cleaner. If you looked at any individual diff, you would approve it.
The agent was failing because it did not, on its own, promote a repeated local failure into a structural question. It received the same class of bug report four times. It received code review feedback identifying round-trip safety failures three times. It received automated hook interventions flagging data consistency problems twice. At no point did it step back and say: the problem is not that the serializer is slightly wrong. The problem is that the serializer exists.
The moment the work was reframed around the invariant instead of the symptom, the fix became straightforward.
That is the gap teams need to close as they hand more of their codebase to agents. Not better models. Better supervision. The question is not whether your agent can write a regex. The question is whether your process tells the agent when to stop writing regexes and start questioning the architecture.